
11.1 Overview
Logistic regression is the classic, historically prior classification procedure. Modern machine learning analyst, however, provides many alternatives in pursuit of optimal predictive accuracy. With modern computing power, we can experiment with various estimation algorithms, model types, and parameter settings, even for large data sets.
Another widely-employed classification procedure is the decision tree, which, as with logistic regression, can be applied to a classification target variable with two or more classes (labels, levels, values, groups). A decision tree provides a sequence of classifications.
Decision tree: Hierarchical structure of binary decisions.
The process of obtaining the hierarchical structure begins with all of the data and then divides the data into successively more homogeneous groups.
Each binary decision follows from a cutoff value for a feature variable. Prediction examples (instances, samples) with a value larger than the cutoff value into one group, and classify examples with a value less than the cutoff into another group. For example, given the amount of credit card debt as a percentage of income, classify all bank customers with a debt above a certain threshold as rejected for a loan and all customers with a debt below that level as accepted for a loan.
In practice, other variables would also be considered in the final decision for providing or not providing a loan. After the first binary decision, usually, introduce a subsequent decision based on a threshold of a second variable. A sequence of questions results expressed as If-Then rules that, when followed to the end, results in a classification of a given example to one group.
11.2 Example
To illustrate the process of forming a decision tree, return to our (real) data set of an online clothing retailer that predicts a customer as a man or a woman from their physical measurements. Consider the simpler analysis that relies upon only two features, the predictor variables: hand size and height. Figure 11.1 provides the scatterplot for 340 (actual) customers, with men’s and women’s measurements represented by different colors. With this scatterplot, explore the possibility of predicting man/woman from body measurements.
To accommodate some over-plotting due to the limited number of unique values for the measurements of height and hand size, plot points with partial transparency. However, this adjustment does not fully address the problem because points of different colors can also plot to the same coordinate. When points of only the same color over-plot the same coordinate, the exact number of such over-plots cannot be determined from the graph. Still, the plot serves as a helpful guide to how the decision tree algorithm defines regions of points based on homogeneity.
According to Figure 11.1, the potential for classification from these measurements appears realistic as male and female measurements generally cluster into different areas of the scatterplot. Males tend to the upper-right, and females tend to the lower-left. Given this differentiation, an efficient classification algorithm would generally obtain a successful classification.
The decision tree algorithm proceeds by considering all of the data and then determines the features from which to split the examples into two groups to obtain the maximal homogeneity (sameness) within each group. For this application, derive one group with the proportion of men as high as possible, and a second group with the proportion of women as high as possible.
Evaluate the various proposed splits at each step in the construction of a decision tree model with a homogeneity index. At a given node, everyone in the same class, such as Male or Female, yields a perfectly homogeneous group.
Gini impurity (applied to decision trees): Index of the impurity of a split, which varies from the desired 0 for perfect homogeneity (equality) to maximum inequality at 1, which indicates a random distribution of the data values across the groups.
The closer the Gini index to zero, the better. A Gini index of 0.5 denotes equally distributed elements across the groups, that is, the classes. For example, as shown in Figure 11.3, the Gini impurity of the initial or root node of 170 Females and 170 Males is 0.5.
For example, to classify a customer as a man or a woman from physical dimensions such as hand size and height, first classify each individual instance (or sample) according to their hand size as likely male or female. Given the resulting two sets of classifications, then according to height, further partition the derived two groups. The ideal solution, rarely obtained with real data, would consist of a sequence of decisions that lead to only male body types or only female body types, that is, perfectly homogeneous groups, without overfitting the tree to the data.
The Gini index is the default homogeneity index for Python’s sklearn machine learning framework. The estimation decision tree algorithm chooses the split that maximizes the drop in the Gini index. Although the estimation algorithm proceeds by choosing decisions that minimize Gini impurity, evaluate the ultimate fit of the model according to the resulting confusion matrix of true and false positives and true and false negatives, as shown below.
11.2.1 Split #1
For a given set of data, examine each feature one-by-one. The decision tree algorithm identifies each feature’s optimum value that splits the data into the most homogeneous groups.
Decision boundary: Value of a feature variable chosen that splits the values of the variable into two subsets.
Given the possible splits for all the features, the algorithm chooses the one split that yields the most homogeneity among the various groups.
The competition between the features yields hand size as the winner, the feature with a cutoff value that yields the most homogeneous groups. The first split from the decision tree algorithm identifies the following decision boundary:
- Female with hand size < 8.125
- Male with hand size \(\geq\) 8.125
The decision tree model with a single split of the data provides a simple prediction: Predict Female if hand size is less than 8.125, and predict Male otherwise.
For the first node, the estimation algorithm considers all the data to derive the evaluation of the first split.
root: The node at the top of the inverted tree structure indicates the first split, on all the data.
The basis for the chosen split follows from the structure of the data shown in Figure 11.2. The estimation algorithm selects the value of 8.5 for hand size, which divides the men and women as effectively as possible for these two groups. The group consists of mostly brown points (males) are on the right side of the line, and mostly blue points (females) on the left.

The resulting output of the decision tree algorithm for this single binary split at a Hand circumference of 8.125 inches appears in Figure 11.3. The root node begins with all 340 samples, 170 females and 170 males, so the Gini Coefficient is 0.5. Each tree node presents the corresponding prediction. This simple decision tree only has a depth of 1, so temporarily, until the tree expands to more depths, the bottom two nodes are leaves, nodes at the bottom of the tree.
For the first node, given the even split of Male and Female samples, because F precedes M in the alphabet the algorithm arbitrarily predicts Female, which signifies Female as the True value of the subsequent split. Also, because of the alphabetical ordering, by default, to define the reference group the dummy variable conversion arbitrarily leaves out the first group.
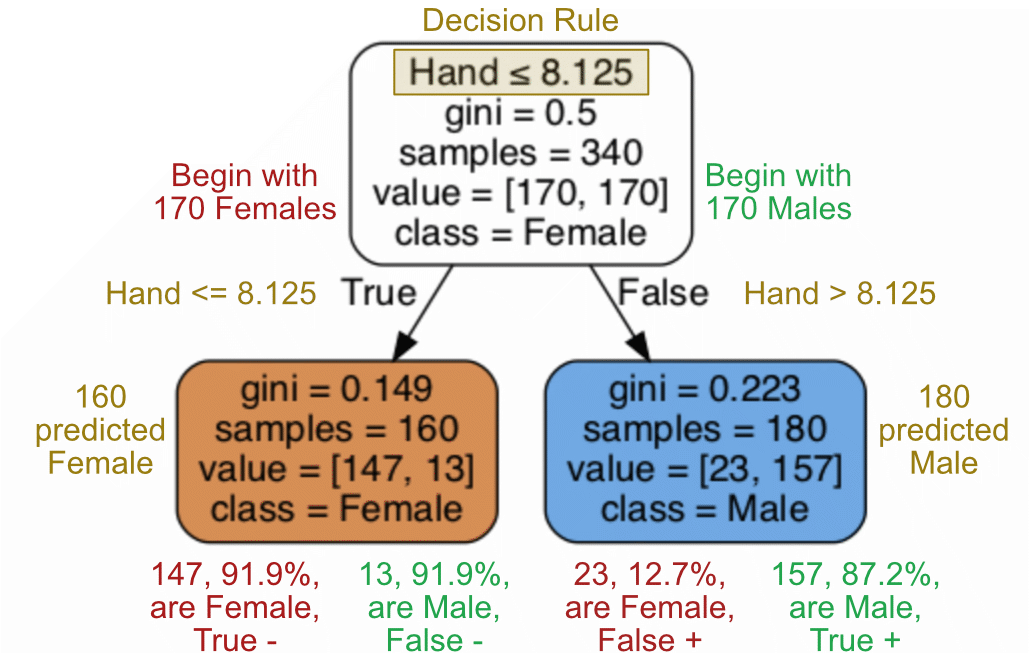
Interpret a decision tree, such as in Figure 11.3, according to the following rules.
- The decision rule is listed at the top of each node that is not a leaf (bottom row). The decision for each sample at that node follows from the specified cutoff value of a single variable.
- The bottom row of the tree, the leaves, do not have a decision rule. Instead, the leaves represent the predicted label, the final classification into one of the two groups or classes.
- If a sample satisfies the decision rule at a node, classify the sample by following the left arrow that branches from the node. Otherwise, follow the right-arrow branch.
- Read class= as predicted class=, the model’s classification for all of the samples located at that node.
- The prediction for the class at any node is the group with the largest number of samples at that node.
- Each value has two entries. The entry on the left is the number of samples in the predicted class of the root node, the direction of the left-arrow branch.
- The four values resulting from the two nodes that split off their shared parent node specify the number in each of the following groups: True +, True -, False +, False -.
- The intensity of the color for each node in the decision tree indicates the extent of correct classification in terms of the Gini Coefficient. More saturated color indicates a lower Gini, so more confidence in the classification.
How accurate are predictions with this simple decision tree model with only one decision rule? The confusion matrix in Table 11.1 follows from this simple classification rule based on Hand size, all values of the matrix taken from the temporary leaves of the decision tree in Figure 11.3.
| actual | pred F | pred M |
| F | 147 | 23 |
| M | 13 | 157 |
The result of this first split at a Hand circumference of 8.125 inches is the Female group with 147 females and 13 misclassified males. The corresponding Male group has 157 males and 23 misclassified females. This single split decision tree model resulted in a classification accuracy of 89.4%.
\[ \mathrm{accuracy=\frac{true \; positives + true \; negatives}{all \; outcomes}=\frac{147 + 157}{147+13+157+23}=0.894}\]
Will additional complexity improve the predictive efficiency of the model? For a decision tree model, add complexity with an additional split of each of now two groups from the first split.
11.2.2 Split #2
The first split to obtain the decision tree model in Figure 11.3 partitioned the complete data set into two groups, represented by the points to the left of the vertical line in Figure 11.2, and the right of the line.
This first split resulted in a tree of one-level depth.
Tree depth: The number of If-Then statements evaluated before classifying an example (instance, sample) into one of the criterion groups.
To obtain a more complex model with two levels of depth, apply the same logic from the first split, but now separately applied to each partition. Repeat this process for each existing data partition, of which only two partitions exist after the first split.
First, consider the data partition to the left of the vertical line in Figure 11.2, that is, predict Female. Where to place a horizontal line representing height that divides only that set of partitioned data into maximally homogeneous groups? Find more blue points toward the bottom of the partition and more brown points at the top. Figure 11.4 displays the resulting horizontal line computed by the decision tree algorithm for a height of 69.5 inches.

Apply the same logic to the second partition of data, those points to the right of the vertical line in Figure 11.2 and Figure 11.4. In this partition, the horizontal line is lower than for the first partition to more effectively separate the blue points at the bottom of the partition from the brown points. Figure 11.5 illustrates this decision boundary for a height of 65.5 inches.

From these partitions, create the decision tree for this two-depth model shown in Figure 11.6. Again, lighter shades indicate a greater percentage of mis-classifications.
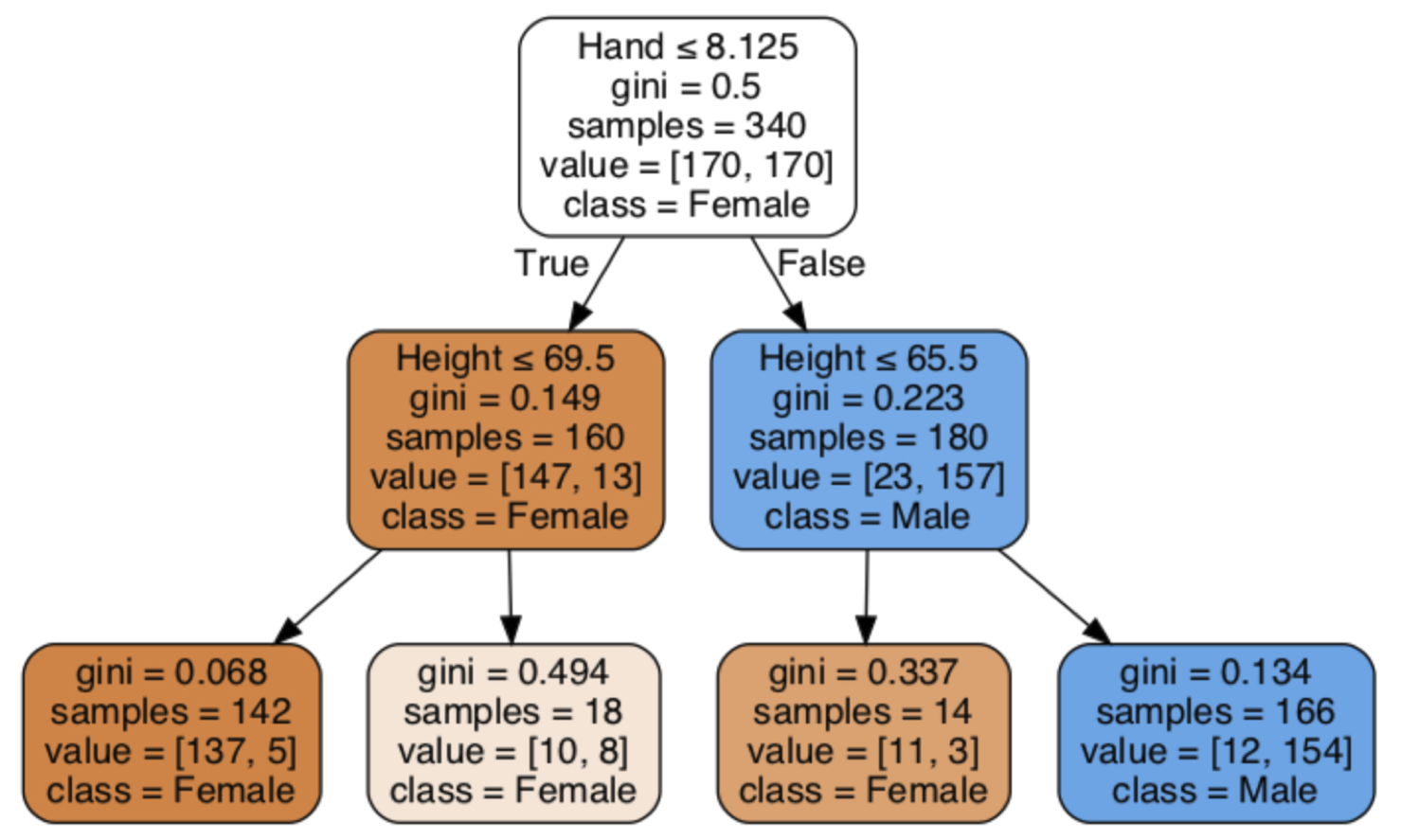
At the second level of depth, find only one node that predicts Male, the node on the extreme right. The two sequential decision rules that predict Male for this node begin with all customers in the data set with a hand size greater than 8.125 inches, and then from those 180 customers, the 166 customers with a height greater than 65.5 inches.
leaf: A node at the bottom of the decision tree, which no longer splits, the final level of grouping.
The remaining three leaves predict Female. The leaf with the lowest percentage of misclassifications for all the leaves is at the extreme left in Figure 11.6. The decision rules correctly classify 137 of the 142 customers, with a hand size less than or equal to 69.5 inches and a height less than 69.5 inches, as Female. Accordingly, that leaf has the lowest Gini index of 0.068.
The leaf second from the left in Figure 11.6, which corresponds to the partition at the top left of Figure 11.5, provides the least accuracy. Customers with a hand size less than or equal to 8.125 inches yet are taller than 69.5 inches are almost evenly split between Female and Male. The slight tilt toward Female, 10 females versus 8 males, results in a prediction of Female for those customers. From a decision making perspective, the application of the model might avoid predicting Gender for tall customers with smaller hands, returning the result of Undecided. The machine learning analyst should evaluate if the information provided by additional body measurements provides information that more reliably distinguishes between males and females in this group.
The correct and incorrect classifications for the leaves in Figure 11.6 provide the information needed to generate the resulting confusion matrix. The total mis-classification of Male for predicted females is \(5 + 8 + 3 = 16\), the total number of false negatives as gathered from the three most left-ward leaves. The one leaf for predicting males indicates 12 mis-classifications, false positives. Table 11.2 presents the complete confusion matrix.
| actual | pred F | pred M |
| F | 158 | 12 |
| M | 16 | 154 |
From the confusion matrix, the computation of accuracy quickly follows.
\[ \mathrm{accuracy=\frac{true \; positives + true \; negatives}{all \; outcomes}=\frac{158 + 154}{158+16+154+12}=0.918}\]
The second split increased accuracy by more than 2% points. Will a third split accomplish the same or more?
11.2.3 Split #3
The third data split returns to the feature hand size to further partition each of the four partitions. Focus on the top-left partition that yielded 10 females and 8 males for the second level split, which is further partitioned for the third level as shown in Figure 11.7.

Further considering hand size, the algorithm partitions the three Female points with a hand size below 7.75 inches. A new leaf, at the third level, contains those three correct Female classifications. The remaining confusion centers on the remaining 15 people from that original partition, seven females and eight males, as illustrated in the tree diagram in Figure 11.8, and also the corresponding shaded partition from the third split in Figure 11.7. The confusion in this remaining group consists of taller customers with a hand size just slightly lower than the threshold from the original hand size decision boundary.
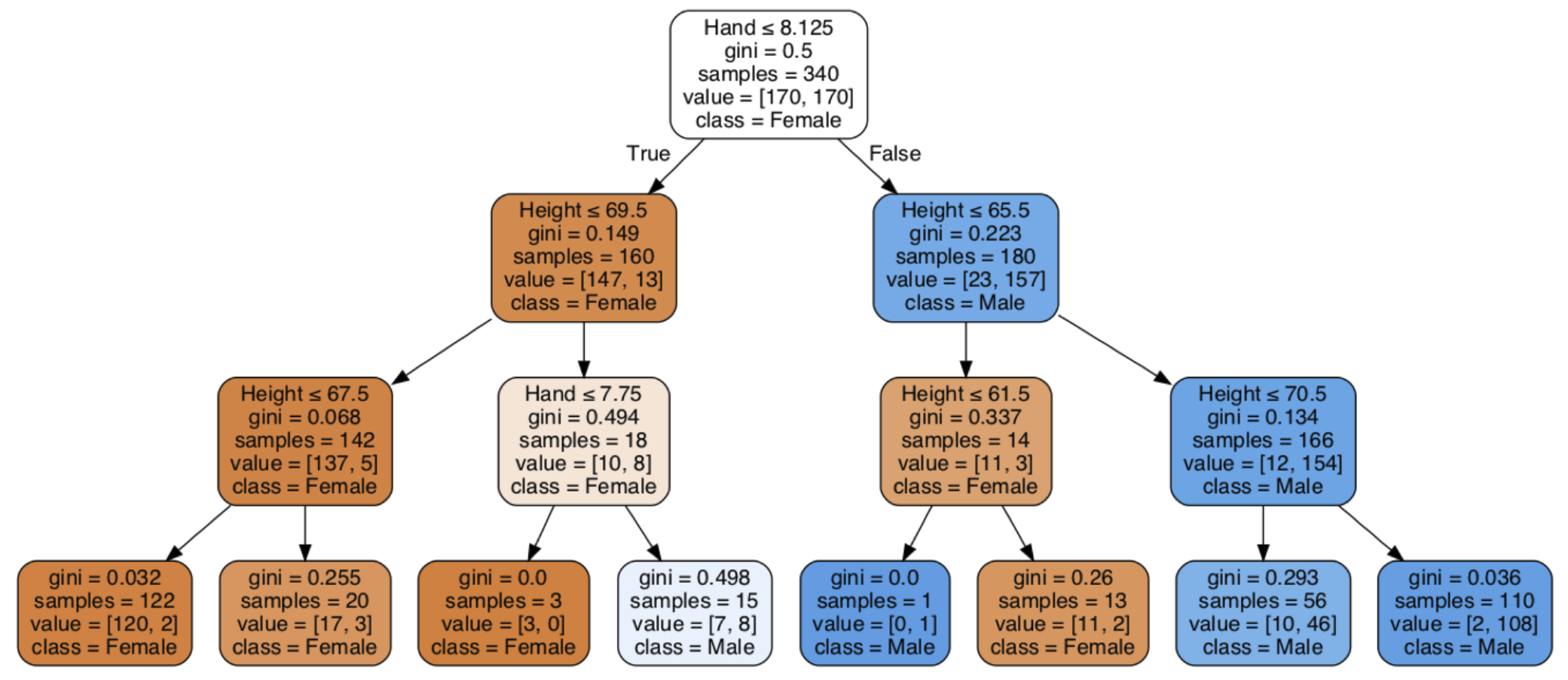
Construct the confusion matrix from the information in now the \(2^3=8\) leaves. The three male leaves on the right have a total of 12 misclassified females, false positives in this context of a male reference group. The leaf with the most confusion, seven females and eight males, contributes another 7 false positives, for a total of 19.
Table Table 11.3 presents the full confusion matrix for evaluating this three-level decision tree.
| actual | pred F | pred M |
| F | 151 | 19 |
| M | 7 | 163 |
Computation accuracy as follows.
\[ \mathrm{accuracy=\frac{true \; positives + true \; negatives}{all \; outcomes}=\frac{163 + 151}{163+7+151+19}=0.924}\]
Accuracy increases only slightly from the two-level tree, a proportion of 0.06. The slight increase in accuracy is accompanied by a decrease in sensitivity (recall), with 12 false positives for the two-level tree and 19 false positives for the three-level tree. In this context, the two-level tree would generally be preferred.
We also see from the decision tree in Figure 11.7 that there is a wide variation inaccuracy across the different leaves. People with a hand size greater than 8.125 inches and taller than 70.5 inches, 108 out of 110 people were correctly classified as male. Accordingly, the Gini coefficient is close to zero, 0.036. At least for this sample, accurate classification for these people is \(\frac{108}{110}\)=98.2%.
In contrast, consider the leaf where males and females are the least well distinguished, with a Gini coefficient of 0.498, the pale blue leaf. For these people, the men have smaller hands than most men, less than 8.125, according to the first level decision. However, their smaller hand size is not by much, with a hand size greater than 7.75 inches according to the third level decision. The second-level decision indicate that these men also tend to be shorter, with their height less than 69.5 inches. So, people with hand sizes close to 8.125 but height less than 69.5 inches are difficult to classify into male or female on the basis of this information alone.
11.3 Overfitting
A decision tree model with three levels of depth did not improve the two-level model. What happens as the model becomes more complex as more levels are added? Is there some advantage? The answer: No.
As discussed in the Section #4 on prediction error, the training data fit can be too good, the estimated model can overfit the data. As the model is revised to become increasingly complex, there are more opportunities for the learning algorithm to properly account for all males and females from their respective body measurements in this specific data set.
With sufficient complexity, a model can achieve perfect prediction on the training data by modeling idiosyncratic sampling error.
The ability of the derived decision rules to classify perfectly from the training data is of no practical consequence because the model already knows the correct classification of each person in the training data.
What happens when the complexity of the decision tree model for the Gender prediction analysis grows to 10 splits? The result is an overfit model, illustrated in the following table for a 5-fold cross-validation. Training data accuracy, listed in the column train_accuracy, for each of the five splits assessed by the Gini coefficient, is perfect. The 10-split model perfectly classifies male and female body types in the training data.
The difficulty is that true predictive accuracy, here labeled test_accuracy, averages 0.891 over the five splits, less than the 0.921 for the two-split model. Moving from two to 10 splits worsens predictive fit instead of improving fit.
fit_time score_time test_accuracy train_accuracy test_recall \
0 0.004 0.009 0.882 1.0 0.889
1 0.003 0.004 0.882 1.0 0.842
2 0.004 0.006 0.941 1.0 0.933
3 0.002 0.004 0.897 1.0 0.889
4 0.002 0.004 0.853 1.0 0.833
train_recall test_precision train_precision
0 1.0 0.889 1.0
1 1.0 0.941 1.0
2 1.0 0.933 1.0
3 1.0 0.914 1.0
4 1.0 0.833 1.0 ` Although overfitting with a too complex model is the more general problem, consider its opposite, underfitting. In this example, the decision tree with just one level of fit did not match the tree’s performance on the testing data with a depth of two. The one-depth model that underfits the data is too simple. As always, a primary challenge in building machine learning models seeks the optimal balance between underfitting and overfitting. As previously stated, the best model achieves parsimony. For a given data set, the model should be as simple as possible without sacrificing fit but no simpler.
11.4 Hyper-Parameter Tuning
11.4.1 Parameter vs. Hyper-parameter
Parameters are what the model learns from the data, while hyperparameters are what the analyst decides to guide the learning process.
Or even more concisely:
Parameters are learned; hyperparameters are chosen. What does the machine learn in an application of machine learning? The chosen estimation algorithm estimates the values of the model’s parameters from the training data. An example of such parameters are the linear weights of the features in a linear model, the \(b_i\). Another example is the split at each level implemented by the decision tree algorithm.
Model parameter: A quantity estimated from the data that defines the expression of a specific trained model, typically chosen to minimize prediction error during training.
Fit a specific linear model that predicts a value of \(y\) to the data to estimate the values of its parameters, the \(y\)-intercept and the slope coefficient for each feature or predictor variable. Fit a specific decision tree to the data to obtain the tree structure that labels a value of \(y\).
However, the analyst sets other characteristics of the model.
Hyperparameter: A characteristic of the model set by the analyst before learning begins.
Parameters are what the model learns from the data to optimize fit, while hyperparameters are what the analyst decides to guide the learning process. Parameters are learned; hyperparameters are chosen.
Hyperparameters for decision trees include the number of features evaluated at each node and the maximum depth of the resulting decision tree. Each value of a hyper-parameter defines a specific model, such as a tree depth of four versus a tree depth of five. The learning algorithm then estimates the values of the parameters present in that specific model.
How does a model with a different tree depth perform? Investigating these questions results in another set of more general characteristics regarding each model for which the machine learns the values of the model’s parameters. We can systematically explore combinations of different hyperparameters by evaluating the fit of each resulting model to help choose the best form of the model.
11.4.2 Grid Search
The Python sklearn environment provides a formal procedure for the ultimate fishing expedition, a data scientist’s dream expedition. The sklearn machine learning framework provides for systematically investigating how a class of related models perform in terms of predictive efficiency for all possible combinations of different values of hyperparameters. For example, how is classification accuracy affected by moving from a depth of three levels to four levels? Do five features increase classification accuracy with more than three features?
Efficient analysis of the impact of different hyper-parameter values on model fit systematically changes their values and evaluates the corresponding predictive accuracy of the resulting models.
Grid search: Investigate the performance of related models by systematically changing the values of hyperparameters.
Adding a grid search to an analysis defines the following progression for doing supervised machine learning:
- Especially if a large data set constrains machine time, begin with a single training/test split of the data to understand if the model appears to have some validity.
- If promising, generalize this single split for that model to a \(k\) splits with a \(k\)-fold cross-validation of \(k\) training/testing splits.
- Generalize beyond the single model with a grid search in which each model configuration, such as a specific combination of tree depth and number of features, is analyzed with its own \(k\)-fold cross-validation.
The only downside to this grid search procedure is computer time, perhaps of consequence for massive data sets. Exploring two hyperparameters with five different values yields \(5*5=25\) different models to investigate. Also, consider the desirable cross-validation. Five cross-validations of each combination of the five levels of the two hyperparameters result in \(5*5*5=125\) separate analyses. The advantage is that the analyst can examine the five analyses of fit for each of the 25 models and then choose the best model in terms of the optimal combination of model and parsimony.
Pursuing the best alternative minimizes the prediction error from applying a model estimated from training data to new testing data. A warning from traditional statistics is to refrain from embarking on these fishing expeditions, more or less randomly searching for the best-fitting model. That warning is real, but only when the same data are continually re-analyzed or other characteristics of the data are transferred to the testing data.
Data leakage: Characteristics of the data used to train the model inadvertently influence the testing data on which the model is evaluated.
A proper machine learning analysis avoids data leakage to ensure to always test the model on new data entirely separated from any influence of the training data.
The most apparent form of data leakage evaluates model fit on the data in which it was trained. More subtle influences also are possible. For example, standardizing all of the data before splitting into training and testing sets results in the both data sets sharing data with the same metric. More properly, standardize the training and testing data separately.
The good news is that if we avoid data leakage, we can “fish” as much as we wish because any chance optimization on the training data by definition does not generalize to testing data. To our benefit, sklearn makes this fishing expedition easy. The application of machine learning does not apply newly discovered laws of statistics. Instead, it relies upon access to modern computing power and large data sets to accomplish analyses that were either impossible or impractical in earlier times.
11.4.3 Three-Way Data Splits
As always, evaluate each model beyond the training data to assess generalization. With hyperparameters, there are now multiple models with different hyperparameter values trained on the training data, and each must be evaluated on data not used for training. If all models are evaluated on what was previously called the test set — and the best model is chosen based on that — the test set is no longer an unbiased estimate of generalization.
When introducing hyperparameters into model selection, a third data set is needed to evaluate the final chosen model. Ideally, evaluate hyperparameters with three data splits instead of the standard training/testing data split. Describe the three-way split as a training/validation/testing data split.
With hyperparameters, ideally follow the following three step process for selecting the optimal model.
Training data: Train multiple models with different hyperparameters on the training set.
Validation data: Evaluate each model with different values of hyperparameters. Choose the hyperparameters with the lowest validation error.
Test data: Then evaluate the final, chosen model on the test set for an unbiased estimate of generalization.
Once the initial model is obtained from the analysis of the training data, analyzing the application of the model to new data may boost prediction efficiency with additional tuning of the model. However, once any kind of adjustment is made to a model on a new data set, then that new data set can no longer serve as an unbiased test of prediction efficiency. If such adjustments are made, then the data set is not testing data, but validation data. The more adjustments, the more potential bias introduced into the evaluation of prediction efficiency, shown in Figure 11.9.

Given the assessment of the hyperparameter values on the validation data, then pursue the evaluation of prediction efficiency on what is entirely new data, previously unencountered by the model, the third data set, the testing data. As with just two splits of the data into training and testing data, the testing data must always be previously unseen data by the model estimation process. Without the validation data set, the third data set, we would have no way to evaluate the chosen hyperparameter values on new data to avoid data leakage. Of course, three splits requires more data than two splits, so sometimes this luxury is not available.
11.4.4 Decision Tree Overfitting
Decision trees provide one of the most interpretable models in machine learning. Statistical knowledge is not required to understand and apply a specific decision tree. Unfortunately, decision tree models tend to overfit, to have poor performance on the new data needed for prediction. Accordingly, the models tend to be somewhat unstable, to have high variance, which means much different models generally result from relatively small changes in the data.
Local optimization: Iterate with gradient descent to a solution by optimizing the consequences of the decision at each step of the process without referencing the best, overall global solution.
The decision tree solution follows local optimization. The problem is that there is no guarantee that optimizing each step of the iterative solution process provides the best possible overall solution.
Suppose one feature barely provides more homogeneous groups at the chosen decision boundary than does a second feature. Also, suppose that the second feature, if it had been chosen, would eventually lead to a decision tree that provides a more homogeneous solution in the leaves than for the solution obtained after choosing the first feature. The decision tree algorithm always selects the following feature and associated decision boundary only regarding optimization at each decision boundary. There is no global consideration at any point in the process of obtaining the entire solution from root to leaves.
A new type of estimation algorithm was developed to address this short-coming of decision trees and other machine learning procedures. Moreover, as with decision trees, classification can be made for target variables of more than just two alternatives. And, regression versions are available for prediction of continuous variables as well.
11.5 Ensemble Methods
To address the dual issues of increasing predictive power while avoiding overfitting, build a predictive model based on many different models that train on different random subsets of the data.
Ensemble model: Combine the results of randomly selected component models that are learned on different random subsets of the data to form a more robust predictive model.
The more general model acts as a manager, a collective intelligence. The input to the more general model are the predictions of the component models. Each component model has its advantages and disadvantages. The manager model evaluates each component model’s prediction for each data example and then learns which component performs the best in a given situation. Particularly when the component models disagree, the general model learns to optimally choose between the competing predictions, to predict from a collective consideration of their individual predictions.
Ensemble methods produce the most accurate predictive models and tend to overfit less. Hence, they are relatively robust to small changes in the data. In an ensemble of separate predictive models, the models compensate for each other’s limitations, with the result that the ensemble more readily achieves more accurate prediction than any of the constituent models.
11.5.1 Bagging: Random Forest Classifier
The current state of predictive modeling is dominated by successful ensemble models that typically outperform a single predictive model, including decision trees. A decision tree is a single tree. A random forest is a forest of trees, a bagging procedure.
Bagging (bootstrap aggregating): A type of ensemble method that builds several models using random samples with replacement, or bootstraps, from the training data. Each model is trained separately, and their results are combined (aggregated) by voting for the classification or averaging for regression.
Bagging helps make predictions more stable and reduces the chance of overfitting. Bagging reduces variance and helps prevent overfitting, particularly for high-variance models like decision trees. Instead of relying upon a single model for predictions, combine multiple predictive models into a more general model based on the separate evaluation of each model.
Random forest classifier: A bagging procedure that constructs a series of decision trees where each tree is based on a different random sample of (a) the data, with replacement (bootstrapping), and (b) the classification of an example is the result of the majority vote from the different trees in the forest.
Each individual decision tree in the forest is constructed from a random sample of the training data and a random sample of the features from which the classification is constructed. Each tree is constructed from different information.
Each decision tree yields its own predicted classification, the label, from each set of the values of the features, the predictor variables.
Bagging: A machine learning technique for reducing the variance of a model by integrating multiple models trained on distinct data samples.
Bagging is the process of generating multiple models, each with a subset of the data and potentially a subset of features, and then combining them to produce a more robust model less prone to overfitting. The result is a procedure that typically returns a higher level of classification accuracy than a single decision tree. Individual models might overfit to their specific data subset, but averaging many models reduces this variance and creates a more robust predictor.
However, a random forest does not produce a single decision tree that explains how the prediction is obtained. Instead, the result is an integration of the output of many different trees. Obtain enhanced predictive ability at the expense of easy interpretability .
11.5.2 Boosting: Gradient Boosting
Another type ensemble method is boosting.
Boosting: An ensemble technique in which models are trained sequentially such that each model focuses on correcting the errors of the previous one.
Boosting is a type of ensemble model, just like bagging, but it builds models in a smarter, step-by-step way instead of all at once.
Gradient Boosting: A type of boosting where each new model fits to the residuals (errors) of the previous model, using gradient descent to minimize a loss function.
As with the random forest procedure, gradient boosting is usually, but not necessarily, directed towards refining decision trees. When applied to decision trees we can use the term gradient boosted trees. When applied to the prediction of a continuous variable, we refer to the estimation procedure as gradient boosted regression.
11.5.3 General Procedure
Random forest works well with almost no tuning considering primarily n_estimators, and perhaps max_depth, min_samples_leaf. Random forest is also preferred for small data sets. Gradient boosted trees requires more tuning such as learning_rate, n_estimators, and max_depth/leaves. The reward for the additional effort is typically higher but there is more of an overfitting risk with extensive model tuning.
Start with DecisionTreeClassifier to illustrate a specific decision and provide a concrete explanation of the classification process. For a more sophisticated potentially more accurate model, move to RandomForestClassifier to set a baseline. If you need better metrics, move to gradient boosting with early stopping and tuning. Gradient boosted trees generally yield top performance once you tune.
Two standard widely current boosting classifiers are the sklearn HistGradientBoostingClassifier and the , consider XGBoost classifier, XGBClassifier which is specified with sklearn style code but is a separate add-in. Or, if the model contains many categorical predictors, consider CatBoost. The HistGradient boosting is specifically adapted to run on a single computer. The XGB classifier excels on distributing computing with GPU’s. XGB what’s the additional tuning and work may provide the best overall prediction, especially on larger data sets. That said, HistGradient boosting remains competitive and simpler to run, staying entirely within the sklearn framework.
Moreover, there is no need to impute missing data values for HistGradient or XGBoost tree models because they handle missing values natively.
%%%%%%%%%% https://machinelearningmastery.com/how-to-decide-between-random-forests-and-gradient-boosting/
Introduction
When working with machine learning on structured data, two algorithms often rise to the top of the shortlist: random forests and gradient boosting. Both are ensemble methods built on decision trees, but they take very different approaches to improving model accuracy. Random forests emphasize diversity by training many trees in parallel and averaging their results, while gradient boosting builds trees sequentially, each one correcting the mistakes of the last.
This article explains how each method works, their key differences, and how to decide which one best fits your project.
What is Random Forest?
The random forest algorithm is an ensemble learning technique that constructs a collection, or “forest,” of decision trees, each trained independently. Its design is rooted in the principles of bagging and feature randomness.
The procedure can be summarized as follows:
Bootstrap sampling – Each decision tree is trained on a random sample of the training dataset, drawn with replacement Random feature selection – At each split within a tree, only a randomly selected subset of features is considered, rather than the full feature set Prediction aggregation – For classification tasks, the final prediction is determined through majority voting across all trees; for regression tasks, predictions are averaged
What is Gradient Boosting?
Gradient boosting is a machine learning technique that builds models sequentially, where each new model corrects the errors of the previous ones. It combines weak learners, usually decision trees, into a strong predictive model using gradient descent optimization.
The methodology proceeds as follows:
Initial model – Start with a simple model, often a constant value (e.g. the mean for regression) Residual computation – Calculate the errors between the current predictions and the actual target values Residual fitting – Train a small decision tree to predict these residuals Model updating – Add the new tree’s predictions to the existing model’s output, scaled by a learning rate to control the update size Iteration – Iterate the process for a specified number of rounds or until performance stops improving
Key Differences
Random forests and gradient boosting are both powerful ensemble machine learning algorithms, but they build their models in fundamentally different ways. A random forest operates in parallel, constructing numerous individual decision trees independently on different subsets of the data. It then aggregates their predictions (e.g. by averaging or voting), a process that primarily serves to reduce variance and make the model more robust. Because the trees can be trained simultaneously, this method is generally faster. In contrast, gradient boosting works sequentially. It builds one tree at a time, with each new tree learning from and correcting the errors of the previous one. This iterative approach is designed to reduce bias, gradually building a single, highly accurate model. However, this sequential dependency means the training process is inherently slower.
These architectural differences lead to distinct practical trade-offs. Random forests are often considered more user-friendly due to their low tuning complexity and a lower risk of overfitting, making them an excellent choice for quickly developing reliable baseline models. Gradient boosting, on the other hand, demands more careful attention. It has a high tuning complexity with many hyperparameters that need to be fine-tuned to achieve optimal performance, and it carries a higher risk of overfitting if not properly regularized. As a result, gradient boosting is typically the preferred algorithm when the ultimate goal is achieving maximum predictive accuracy, and the user is prepared to invest the necessary time in model tuning.
FEATURE RANDOM FORESTS GRADIENT BOOSTING Training style Parallel Sequential Bias–variance focus Reduces variance Reduces bias Speed Faster Slower Tuning complexity Low High Overfitting risk Lower Higher Best for Quick, reliable models Maximum accuracy, fine-tuned models
Choosing Random Forests
Limited time for tuning – Random forests deliver strong performance with minimal hyperparameter adjustments Handles noisy features – Feature randomness and bootstrapping make it robust to irrelevant variables Feature-level interpretability – Provides clear measures of feature importance to guide further data exploration Choosing Gradient Boosting
Maximum predictive accuracy – Identifies complex patterns and interactions that simple ensembles may miss Best with clean data – More sensitive to noise, so it excels when the dataset is carefully preprocessed Requires hyperparameter tuning – Performance depends heavily on parameters like learning rate and maximum depth Less focus on interpretability – More complex to explain, though tools like SHAP values can provide some insights Final Thoughts
Random forests and gradient boosting are both powerful ensemble methods, but they shine in different contexts. Random forests excel when you need a robust, relatively fast, and low-maintenance model that handles noisy features well and offers interpretable feature importance. Gradient boosting, on the other hand, is better suited when maximum predictive accuracy is the priority and you have the time, clean data, and resources for careful hyperparameter tuning. Your choice ultimately depends on the trade-off between speed, interpretability, and performance needs.