Previous examples of regression models involved continuous variables, both the target variable and the predictor variables, the features. However, the target variable can be categorical, as can the predictor variables. The topic of this section is categorical predictor variables. Of course, least-squares regression analysis requires numerical variables, not categorical labels. There needs to be some way to convert the categories to numbers.
There are many different practical ways by which to convert the values of a categorical variable to numbers.
Key Idea: The choice of the conversion method to numerical variables is important because it determines how the corresponding slope coefficients are interpreted.
In this section, we cover two such methods: dummy coding and effect coding. These two methods are probably the most commonly used conversion rules. Choose the method at corresponds to the of type interpretation you wish for the corresponding slope coefficient of the new numerical variables. How to create these variables and interpret the corresponding slow coefficient is the topic of the following material.
8.1 First Example
One example of a categorical predictor variable is the use of Gender to predict Salary.
8.1.1 Default R Analysis
d <- Read("http://web.pdx.edu/~gerbing/data/SalaryGender.csv")
reg(Salary ~ Gender)
For a data set with two values of Gender, M and F, the analysis provided a slope coefficient that indicated the average mean difference between Males and Females.
In this example, on average, men made \(b_1=\$14,109\) more than women. This analysis does not explain why there is a difference, but it does establish a difference. Reject the null hypothesis of no difference with a \(p\)-value \(=0.042 < \alpha=0.05\).
Where did the predictor variable GenderM come from given that the entered variable into the analysis was Gender? Why does the slope coefficient for GenderM indicate the mean difference between males and females? These questions are answered below.
8.1.2 The Data
Read the constructed toy data set into the d data frame, and then display. The designed simplicity of this data table helps communicate the basic concepts of using a categorical predictor variable to a regression model.
Data Types
------------------------------------------------------------
character: Non-numeric data values
integer: Numeric data values, integers only
------------------------------------------------------------
Variable Missing Unique
Name Type Values Values Values First and last values
------------------------------------------------------------------------------------------
1 Name character 12 0 12 Girija Jenna ... Jordan Colton
2 Group character 12 0 4 A A A ... D D D
3 Score integer 12 0 6 0 2 4 ... 6 8 10
------------------------------------------------------------------------------------------
For the column Name, each row of data is unique. Are these values
a unique ID for each row? To define as a row name, re-read the data file
with the following setting added to your Read() statement: row_names=1
d
Name Group Score
1 Girija A 0
2 Jenna A 2
3 Giovani A 4
4 Hailey B 2
5 Lindsey B 4
6 Khalid B 6
7 Chloe C 4
8 Danny C 6
9 YuChun C 8
10 Regina D 6
11 Jordan D 8
12 Colton D 10
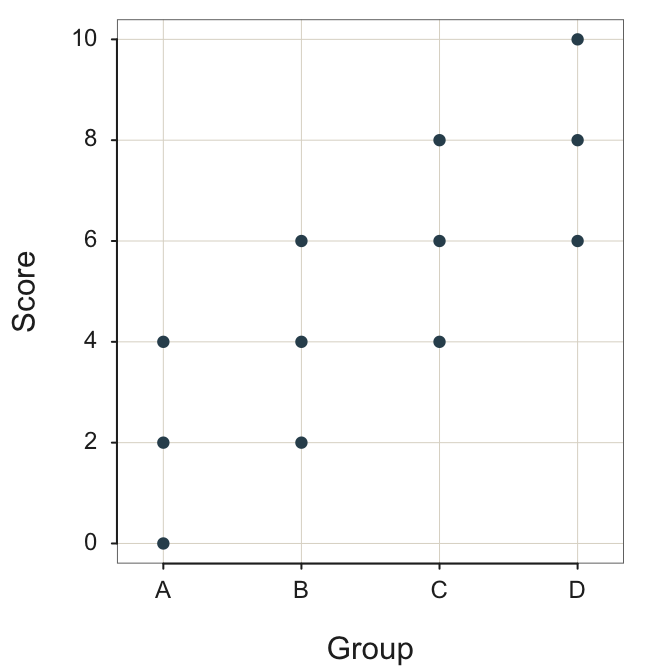
The categorical variable Group has 4 non-numeric levels (groups): A, B, C and D. There are 3 data values of continuous variable Score per group. Plot() generates the corresponding scatterplot. By default, Plot() displays the mean of each group as a larger, dark red circle but here this feature is turned off to visualize only the data.
Plot(Group, Score, quiet=TRUE, means=FALSE)
8.1.3 Descriptive Statistics
Plot() displays the group statistics such as the mean, unless instructed not to by setting parameter quiet to TRUE as in the above function call. Alternatively, obtain those means with the lessR function pivot(), a general function that computes descriptive statistics in the form of a pivot table as named by MS Excel. Read the following function call to pivot() as: For datad, compute the mean of the variable Score.
To be explicit, here include the parameter names in the function call.
pivot(data=d, compute=mean, variable=Score)
With R, however, if the parameter values are listed in the order of their definition (as seen from entering ?pivot), the parameter names do not need to be included in the function call.
pivot(d, mean, Score)
n na mean
12 0 5
The na in the output is for not assigned, so Score_na indicates the number of missing data values for Score, none in this example.
The overall mean of Score, the grand mean, is \(m=5\).
To obtain the summary statistics for each group separately, aggregate the data with the by parameter, the fourth parameter value of the pivot() function. Again, the parameter name need not be indicated, but included here for clarity.
pivot(d, mean, Score, by=Group)
Group n na Score_mean
1 A 3 0 2
2 B 3 0 4
3 C 3 0 6
4 D 3 0 8
The respective group means are \(m_A=2\), \(m_B=4\), \(m_C=6\), and \(m_D=8\). Refer to these means in the subsequent regression analyses.
8.2 Indicator Variables
Begin with the regression analysis with the lessR Regression() function, using the abbreviation reg(). Regression() relies upon the standard base R function lm() for computing the weights of a linear model according to the least-squares algorithm. As such, the following results are the same using either function.
Optionally, save the output of Regression() to an R object called a list, here named r. Writing the result to an R object allows the selective display of only sections of the output, in this example the estimated linear coefficients and associated statistics in this presentation. Define the non-numeric categorical, non-numeric variable Group as the predictor variable in the regression model.
r <-reg(Score ~ Group, graphics=FALSE)
>>> Group is not numeric. Converted to indicator variables.
What did R do here? Regression analysis requires numerical variables. Yet, the analysis ran and generated output from the non-numeric values of variable Group.
R automatically transformed each non-numerical category to a numerical value.
Indicator variable: Numerical representation of a single category of a categorical variable.
Each level of a categorical predictor variable has its own numerical coding. The most common coding scheme for regression analysis that converts categories to numbers, the R default, creates a specific type of indicator variable.
Dummy variable: For each example (row of data), assign a value of 1 if the category occurred and a 0 if the category did not occur.
Variable Group has four values scored as A, B, C, and D in this data set, so four dummy variables can be created. The dummy variable for Category A is 1 if the person is a member of Group A. Otherwise, the value of the dummy variable is 0, etc. Four rows of data follow with the four created dummy variables added to the original data.
Name Group Score GroupA GroupB GroupC GroupD
Girija A 0 1 0 0 0
Regina D 6 0 0 0 1
Giovani A 4 1 0 0 0
Khalid B 6 0 1 0 0
However, the regression analysis output only includes three dummy variables: GroupB, GroupC, and GroupD. What happened to the GroupA dummy variable?
For a categorical variable with four levels, if the value of an indicator variable for three levels is known not to have occurred, the fourth level must have occurred. For example, knowing that the value of the Group is not B, C, or D, then the value must be A. One dummy variable is entirely redundant with, that is, collinear, with the remaining three dummy variables.
This principle of redundancy generalizes to a categorical variable with any specified number of levels.
Redundancy principle: For a categorical variable with \(k\) levels, enter \(k-1\) indicator variables into the regression analysis.
Including four indicator variables in this analysis would introduce perfect collinearity. A least-squares solution is impossible in this situation. (A matrix computed as part of obtaining the solution is not invertible, leading to a condition called singularity).
When creating the dummy variables, by default R does not create a dummy variable for the first level or group of the categorical variable.
Reference group (base): Value of a categorical variable for which no indicator variable is created.
R defined Level A as the reference group not because the data values of A are listed first in the data table. Instead, by default, R orders the levels of a character variable alphabetically. If the categories, for example, were Male and Female, then by default R would set the Female category as the reference group.
8.3 Regression Analysis
The computed regression coefficients, the weights of the linear model, are defined in relation to the reference group. To understand why, consider the example regression model with the three indicator variables. To write the regression model, let \(x_B\) refer to the dummy variable for Group B with values of 0 or 1, and similarly for \(x_C\) and \(x_D\).
A member of GroupA scores zero on the three indicator variables. The values of \(x_B, x_C \; \textrm{and} \; x_D\) vanish, leaving only the intercept in the regression model as it applies to a member of GroupA.
With just an intercept term, the value of the intercept is the mean of Score when Group=A, \(b_0 = m_A\). Knowing that a person is a member of GroupA, the best guess as to their Score is the mean of all the scores in that group.
Now consider a row of data for GroupB. For GroupB membership, \(x_B=1\), and all other indicator variables are 0. The corresponding slope coefficient, \(b_B\), appears in the regression model only for those rows of data with Group=B.
In this context, two terms remain in the model, the intercept and the term for GroupB. Given the intercept is the mean of GroupA, \(m_A\), then the slope for \(x_B\) is necessarily how much membership in GroupB changes the impact on the target variable, here \(y_{Score}\), from GroupA membership.
For a member of GroupB, the slope, \(b_B\), is the difference of the mean of Score for the reference group, those values where Group=A, and the mean of Score for the Group=B group.
\[\hat y_{Score} = m_{A} + (m_{B}-m_{A})\]
As with GroupA, a person’s fitted value of Score who is a member of GroupB is the mean Score for that group, \(m_{A} + (m_{B}-m_{A})=m_B\).
The same logic that applies to GroupB applies to GroupC and GroupD. The slope coefficient for each indicator variable indicates how much the response variable changes, on average, from the baseline established by the reference group. Write the full estimated regression model as follows.
For example, the intercept term is \(m_A=2\), the mean of Score for Group A. The mean of Score for Group B is 4, \(m_B=4\). The slope coefficient for GroupB is 2, which is \(m_B - m_A\).
Dummy variable estimated weights: For the estimated regression model, the intercept is the mean of the reference group and each slope coefficient is the mean of the corresponding group minus the mean of the reference group.
To illustrate for pedagogy, add the indicator variable columns, the three dummy variables, to the original data frame. The regression analysis uses those created dummy variables as the predictor variables.
d
Name Group Score xB xC xD
1 Girija A 0 0 0 0
2 Jenna A 2 0 0 0
3 Giovani A 4 0 0 0
4 Hailey B 2 1 0 0
5 Lindsey B 4 1 0 0
6 Khalid B 6 1 0 0
7 Chloe C 4 0 1 0
8 Danny C 6 0 1 0
9 YuChun C 8 0 1 0
10 Regina D 6 0 0 1
11 Jordan D 8 0 0 1
12 Colton D 10 0 0 1
Now run the multiple regression of target Score directly onto the dummy variables. R did this in the first example, only it automatically created the updated data frame, and then proceeded with the analysis.
r <-reg_brief(Score ~ xB + xC + xD, graphics=FALSE)r$out_estimates
The output is identical to the previous default regression analysis. Here the reliance upon indicator variables, the dummy variables in this example, becomes explicit. Because R automatically did the work in the background to create the dummy variables as predictor variables, this demonstration was pedagogical. However, further customization requires the user to construct the contrast matrix, even by calling an R function designed for this purpose.
Next, find a more detailed explanation of using indicator variables to represent categorical predictor variables.
8.4 The Contrast Matrix
To accept the default R analysis, letting R create the dummy variables and define the first alphabetical level as the reference group, requires no additional exploration. However, to customize the process, choose the reference group, or select another type of indicator variable than a dummy variable. This customization requires knowledge of the underlying process.
Contrast: Weighted comparison of the level of a categorical variable to the other levels.
The basis for coding a categorical variable to numerical is the table of contrasts, called a contrast matrix. The contrast matrix can easily be entered manually for such a simple problem, but here, use the base R contrasts() function to construct the matrix.
The contrasts() function only works with factor versions of categorical variables. Variables of type factor in the R system are the formal declaration of a categorical variable. First convert the variable Group (in the d data frame) from a character string variable to a factor variable. Use the R factor() function, here relying upon the given values of the variable and retaining the same labels for these variables, which could be referenced by other names if so specified with the labels parameter in the factor() function. (Best practice for any analysis converts each categorical variable, whether the values are either non-numeric characters or integer codes, to a factor.)
d$Group <-factor(d$Group)
Store the computed contrast matrix in the object here named dummy, so named because the resulting contrasts are called dummy contrasts. The resulting output computed by the contrasts() function is an R matrix, a different type of data table than the data frame. Convert the matrix to a data frame with the R data.frame() function. Then name the variables in the new data frame with the vector of three names provided to the R function names() and display the data frame.
GroupB GroupC GroupD
A 0 0 0
B 1 0 0
C 0 1 0
D 0 0 1
The name of each indicator variable, each dummy variable in this example, follows from the name of the corresponding group and the name of the categorical variable. Identify the corresponding category by the placement of a 1 in each row of the data table for the dummy variables. The reference group, GroupA, does not have any 1 for the value of any of the three dummy variables. The name of the first dummy variable is the name of the second group, B, and the values of dummy variable B is 1 just for each row of data for that group.
R merges this contrast matrix with the data table to create the enhanced data table that includes the dummy variables. In the homework for this week (and therefore the Final), you will not be required to use R functions to create the data table joined with the indicator variables. Those operations are not the purpose of this class. Instead, you can manually construct the data frame with the indicator variables, such as Excel or a text editor, which works well except for huge contrast matrices, though tedious. For those who wish to understand the more elegant construction of the revised data with R data frame manipulations, refer to the Appendix.
8.5 Change Reference Group
Customize contrasts in many different ways. For example, stay with dummy variables, but change the reference group. As shown, the contrast with the first level as the reference group is the R default for creating dummy variables. In addition to the aforementioned function contrasts(), R also provides a function to calculate the contrast matrix for dummy variables without reference to data, the contr.treatment() function.
Instead of reference to the data, the only required parameter for contr.treatment() is n, the number of levels of the corresponding (not referenced) categorical variable. The parameter base is the reference group from which to compare the other group means, and can be modified from its default value of 1, referring to the first level. Following is the default R contrast matrix for dummy variables of a categorical variable with 4 levels.
cnt <-contr.treatment(n=4, base=1)cnt
2 3 4
1 0 0 0
2 1 0 0
3 0 1 0
4 0 0 1
R, by default, names the variables according to the number of the column position. Change these default column names of this R matrix (not a data frame) with the colnames() function. (The data frame structure uses the names() function to name variables.)
colnames(cnt) <-c("B", "C", "D")cnt
B C D
1 0 0 0
2 1 0 0
3 0 1 0
4 0 0 1
To do a regression analysis with a customized contrast matrix, reference the matrix with the parameter contrasts. This parameter here specified for the lessR Regression() function, in the form of reg_brief(), which makes an internal call to the base R function lm() for which parameter contrasts is defined. To access the contrast matrix, indicate the variable for which the contrast matrix is to apply, here Group, and present the argument as an R list created with the list() function.
r <-reg_brief(Score ~ Group, contrasts=list(Group=cnt), graphics=FALSE)
>>> Group is not numeric. Converted to indicator variables.
Note that this solution is the default R solution. The only distinction is that in the input to the preceding function call explicitly provides the dummy variable contrast instead of relying upon the default.
With the contr.treatment() function, specify coding with a custom reference group according to the base parameter, here the second level of categorical variable Group.
The logic of the values of the estimated coefficients remains the same. Now the reference group, Group=B, has a mean of 4. So the mean of the first group, Group=A, is 2. The difference from the first group, \(g_A - g_B\), is now \(-2\). Apply similar logic to groups Group=C and Group=D.
Straightforward, then, to define the reference group for a regression analysis and not rely upon the default reference group with occurs first in the alphabetical list of the levels or categories of the categorical predictor variable.
8.6 Effect Coding Contrasts
Many pre-defined types of contrasts exist, and custom contrasts also can be constructed. After dummy coding, the most widely-used coding procedure is likely effect coding.
Effect (deviation) coding: The value of each estimated slope coefficient is relative to the overall, grand mean of Score.
Instead of referencing another level of the categorical variable as the reference group, reference the mean of variable Score across all rows of data. Each slope coefficient in this situation indicates if the corresponding group is above or below the overall mean, and by how much.
The R contrast function that computes the effect coding contrast matrix is contr.sum(). Here again the required parameter is n, the number of levels of the corresponding categorical variable. First, obtain the effects coding contrast matrix, an R matrix. Here enter the column names with the colnames() names function, which applies to an R matrix.
By default, effects coding drops the last level of the categorical variable from the analysis. In this example enter the group names for the first three levels of Group.
Effect coding requires that the values for each indicator variable sum to 0. The values that define the column for each indicator variable balance each 1 with a negative 1, \(-1\) for the values of the reference group.
Now apply effects coding to the regression analysis, again with parameter contrasts.
r <-reg_brief(Score ~ Group, contrasts=list(Group=cnt), graphics=FALSE)
>>> Group is not numeric. Converted to indicator variables.
The overall mean of Score, determined previously, is \(m=5\), which for effects coding is the reference, the value of the intercept. The mean of the first group is \(m_A=2\), so relative to the overall mean, the partial slope coefficient is \(-3\). Similarly, \(m_B=4\), so relative to the intercept of \(m=5\), the slope is \(-1\). The only positive slope is for Group C, with mean of \(6\), \(1\) more than the overall mean of \(5\).
Why use effects coding? For a categorical variable with only two values (categories, groups, labels), there is a single indicator variable for that categorical variable. If the indicator variable is a dummy coded variable in the analysis of only two levels of a categorical predictor variable, the resulting slope coefficient, \(m_{B}-m_{A}\), is a direct comparison the two group means, a natural comparison. For more than two groups, however, the reference group of the grand mean may be more meaningful than using another level of the categorical variable as the reference. To move beyond dummy coded indicator variables with R requires moving beyond the R default, as illustrated here.
8.7 Conclusion
To enter a categorical variable into a regression analysis, the k levels of the variable must be converted to k-1 indicator variables. There are many ways to do these conversions, of which dummy coding and effect coding are the two most widely used and the two discussed here. Implement the particular chosen coding scheme according to the composition of the contrast matrix that defines the indicator variables. The guideline for choosing a coding method depends on the way in which the analyst wishes to define the slope coefficients in the analysis. Each slope coefficient of an indicator variable is defined in terms of some comparison with the remaining groups, i.e., levels of the categorical variable. For dummy variables, all of the k-1 slope coefficients are compared against the reference group, which has all values of the indicator variables set at 0. Choose the reference group of most interest, such as a control group in an experiment. Or, with effects coding, define each slope coefficient in terms of the comparison against the overall mean of all the data. Many other possibilities exist but the key is that as an analyst working with categorical variables you wish to define a coding scheme that defines slope coefficients that best answers your questions of interest. `
8.8 Optional Appendix
Here show how to construct the revised data table to include the indicator variables (not a required part of this course). Subsetting and merging are common data manipulation operations. We have some experience with subsetting. Now merging. We wish to add the dummy variables to the data frame to demonstrate what R is doing when it computes a multiple regression with indicator variables, specifically dummy variables in this example.
To construct this revised data frame, merge the data frame of contrasts with the original data table by columns. To do that, we need a variable in common that the two data frames share, the level of the grouping variable. However, each row name of the contrast matrix is the corresponding row name of the table instead of an actual variable.
To copy the row names of a data frame to a variable (column) name, access the row names with the R rownames() function. The R cbind() function joins two data frames together by column. To make the first column of the contrast table the corresponding row name, with a column name of Group, list the first parameter value of cbind() as the row names of the dummy data frame. By default that new variable is named x, so explicitly name first variable of the revised data frame Group. List the second data frame in the cbind() function as the full dummy data frame.
Group xB xC xD
A A 0 0 0
B B 1 0 0
C C 0 1 0
D D 0 0 1
The values of categorical variable Group are now included both as the row names and as an actual variable, Group. We could also delete or change the row names, but they do no harm, so will just leave them.
Merge the data frame with the revised contrast data frame by columns with the R function merge(). The first parameter of merge(), the \(x\) parameter value, is the first listed data frame to merge. The second parameter value, \(y\), is the second listed data frame to merge. To merge the two data frames by columns, identify the common variable in both data frames with the by parameter.
Note that the number of rows in the two data frames are not equal. The data frame that contains the data has as many rows as there are rows of data. The contrast data frame just has a row of data for each indicator variable in the analysis. Even with a common variable, Group, how to merge two data frames with a differing number of rows?
Traditional data base terminology refers to a merge as a join. Here do what is called a left outer join, which means to return all rows from the first listed table, and any rows with matching data values on the by variable from the right table.
To help make sense of this merge, the first six rows of the d data frame, and the complete dummy data frame are listed before the merge.
head(d)
Name Group Score
1 Girija A 0
2 Jenna A 2
3 Giovani A 4
4 Hailey B 2
5 Lindsey B 4
6 Khalid B 6
dummy
Group xB xC xD
A A 0 0 0
B B 1 0 0
C C 0 1 0
D D 0 0 1
With the base R function merge(), merge on the common variable Group, retaining all rows of the first listed data frame. In the call to merge(), list d first and dummy second. Match on the common variable, Group. Add to all rows of the first listed data frame the rows that match according to the shared variable from the second listed data frame, the values of Group. To indicate to retain all the rows of the first listed data frame, set all.x to TRUE.
d <-merge(d, dummy, by="Group", all.x=TRUE)
Here, as shown in the main text, is the revised data table with the indicator variables. Because the variable Group is the variable on which the merge is based, the merge() function has the convention of listing that variable first in its output data frame.
d
Group Name Score xB xC xD
1 A Girija 0 0 0 0
2 A Jenna 2 0 0 0
3 A Giovani 4 0 0 0
4 B Hailey 2 1 0 0
5 B Lindsey 4 1 0 0
6 B Khalid 6 1 0 0
7 C Chloe 4 0 1 0
8 C Danny 6 0 1 0
9 C YuChun 8 0 1 0
10 D Regina 6 0 0 1
11 D Jordan 8 0 0 1
12 D Colton 10 0 0 1