
Nucleic Acids
- huge molecules that carry the genetic information for
an organism
- a polymer composed of phosphate esters linking sugars,
with specific nitrogen bases attached to each sugar unit
Deoxyribose
- in RNA, ribose is the sugar, specifically beta-D-ribofuranose
- in DNA, 2-deoxyribose is the sugar, also with the beta
furanose structure

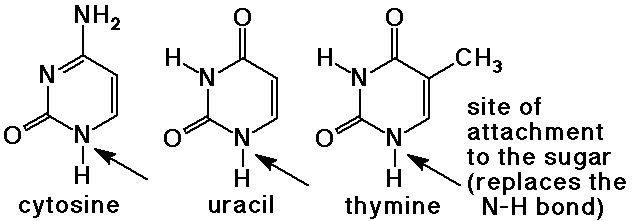
The Nitrogen Bases
- pyrimidine bases have a 6-membered ring with two nitrogens
cytosine, uracil (found in RNA), and thymine (found in DNA)
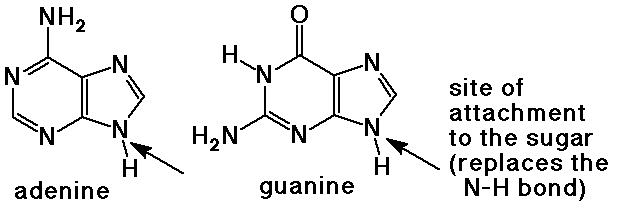
- purine bases have two rings with four nitrogen atoms
adenine and guanine
Nucleosides
- nitrogen base + sugar = nucleoside
- one-letter codes imply the nucleoside (add "d"
for deoxy)
C = cytosine
U = uridine
T = thymidine
A = adenosine
G = guanosine
Nucleotides
- nitrogen base + sugar + phosphate(s) = nucleotide
- ATP = adenosine triphosphate is used as an energy storage
molecule
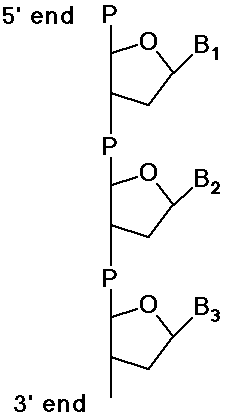
Polynucleotides - DNA and RNA
- polymers of DNA or RNA are named from 5' end to 3' end
Base Pairing
- specific H-bonding can take place between bases on adjacent
strands
in DNA: A & T base pair, G & C base pair
in RNA: A & U base pair, G & C base pair
- the base pairing requires antiparallel directions of the
two strands
the optimum structure for base pairing is a double helix
Replication of DNA
- note that each strand of DNA contains enough information
to duplicate its partner
- DNA is replicated by uncoiling and creating new partners
for each strand
- replication is done by an enzyme, DNA polymerase, using
nucleotide triphosphates (like ATP)
Transcription of Genetic Information from DNA to RNA
- information from DNA is transcribed by copying onto messenger
RNA (m-RNA)
- the m-RNA message matches the original DNA (complementary
to the DNA being copied)
Translation of the Genetic Information into Protein Biosynthesis
- m-RNA brings the genetic information to ribosomes, where
protein biosynthesis takes place
- m-RNA message is read sequentially by its 3-letter codons
- as needed, individual amino acids are brought to the ribosomes
by transfer RNA (t-RNA)
- t-RNA specifically recognizes both the code for an amino
acid and its particular amino acid
The Genetic Code
- each amino acid is represented by a three-letter code
the code is expressed as it appears on the m-RNA, from 5' to
3' direction
- special features of the genetic code (like a language)
- no punctuation - exact starting spot is crucial, must
always move by 3 units
- there is a "stop" code
- duplicate codes - most amino acids have multiple codes
- single-letter changes (especially in the last spot) usually
don't cause a serious misreading of the code
(however, sickle-cell anemia is caused by a single error in the
structure of hemoglobin, in which 6-Glu is erroneously replaced
by 6-Val)
Why is the OH Missing in DNA?
- RNA (both m-RNA and t-RNA) is meant to recycle readily
to read and write messages
- DNA is meant to remain stable
- hydrolysis of the phosphate esters of nucleic acids is
enhanced by the 2'-OH group
in the absence of the 2'-OH group, the phosphate esters are very
stable to hydrolysis
DNA Sequencing
- sizes of DNA molecules measured in kilobases (1000s of
base pairs)
- specific cleavages of DNA can occur with restriction enzymes
- smaller fragments are more easily identified and reassembled
into the original
- the Human Genome Project is an attempt to map the entire
human genetic information in DNA